After asking whether studies that replicate are cited more and finding that this is not the case, I turned to a different analysis that I once did quickly. Namely, I reviewed the N-pact paper by Chris Fraley and Simine Vazire back in 2014. I got excited about the paper, as I’m wont to, and tried redoing their analyses because they had provided the data with their manuscript. I also decided to see if I could find a relationship at the article level as well.
](https://farm4.staticflickr.com/3922/14596336128_9cbfbd34fe_o_d.jpg)
Figure 1: Ample size? From the Internet Archive Book Images
Iro Eleftheriadou, our new RA, helped me clean up the messy code that I wrote at the beginning of my dissertation (for-loops, ugh).
Again, we first needed to get the DOIs by querying the Crossref API. Using the DOIs, we could next get the citation counts. We found 1028 DOIs out of 1042 studies.
Reproducing the original result
Here, I first checked whether I would obtain the same measure as Fraley & Vazire did, when I simply averaged the citations to the articles in this set for each year and journal. Interestingly, I could not, or at least it was substantially weakened. I’m pretty sure that when I did this in 2014, I could reproduce the finding. As you can also see, the association is even weaker when using medians for the citation counts instead of means. However, I can still reproduce their original result with the Thomson-Reuters Impact Factors that I quickly googled. I know the Impact Factor isn’t just a simple metric, but a shady business including some negotiation. Do journal executives sometimes try a pity move, asking for a higher impact factor by highlighting paltry poor sample sizes? It’s impossible to prove this never happened ;-)!
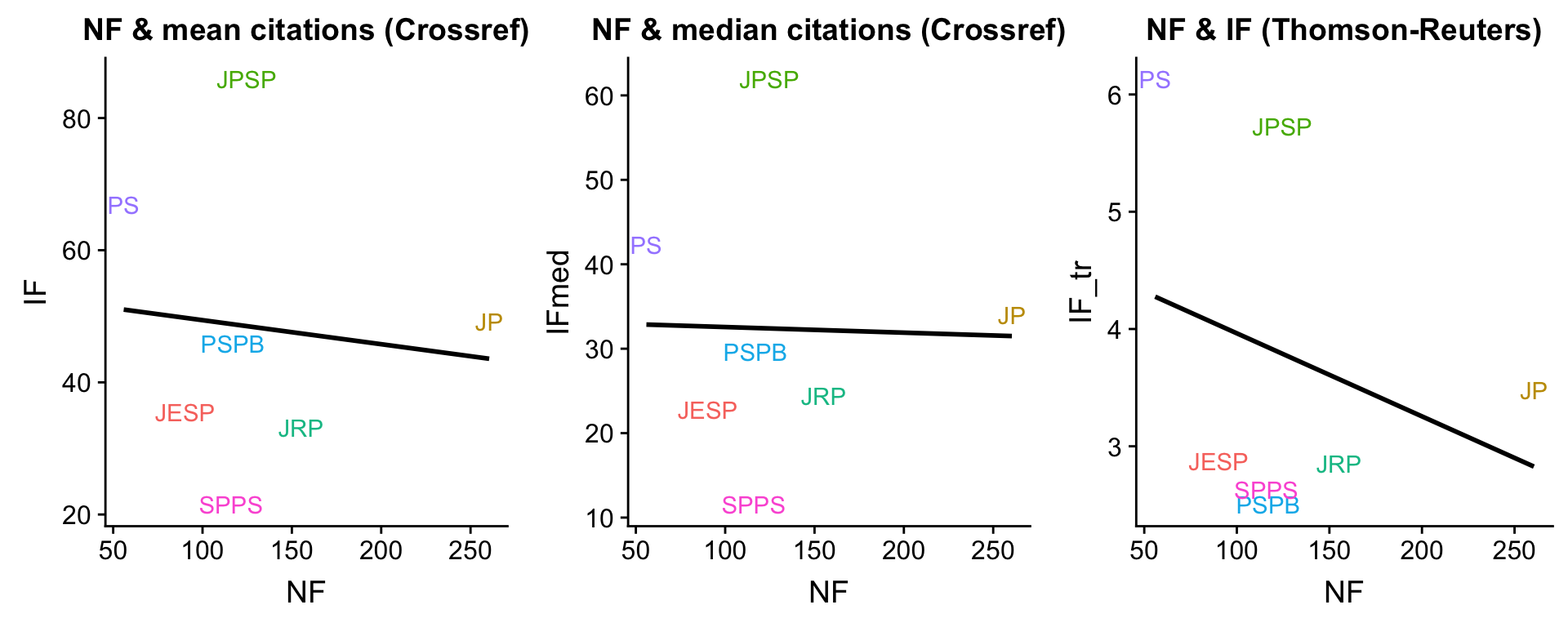
Figure 2: Correlation between IF and NF on the journal level.
Moving to the study level
Fraley & Vazire were interested in highlighting how impact factors do not track a no-nonsense aspect of study quality (all else equal, bigger N is simply better). So, they focused on journals. But I, having recently invested a lot of time into obtaining large samples, was curious to see whether these efforts translated into any sort of citation advantage, and more generally, whether we pay more attention to research that is presumably more reliable.1.
By year of publication
Maybe it takes us some time to notice how paltry a sample size was?2 Or maybe early citations are all about the glamour and flair, but over time the best and biggest studies win out?
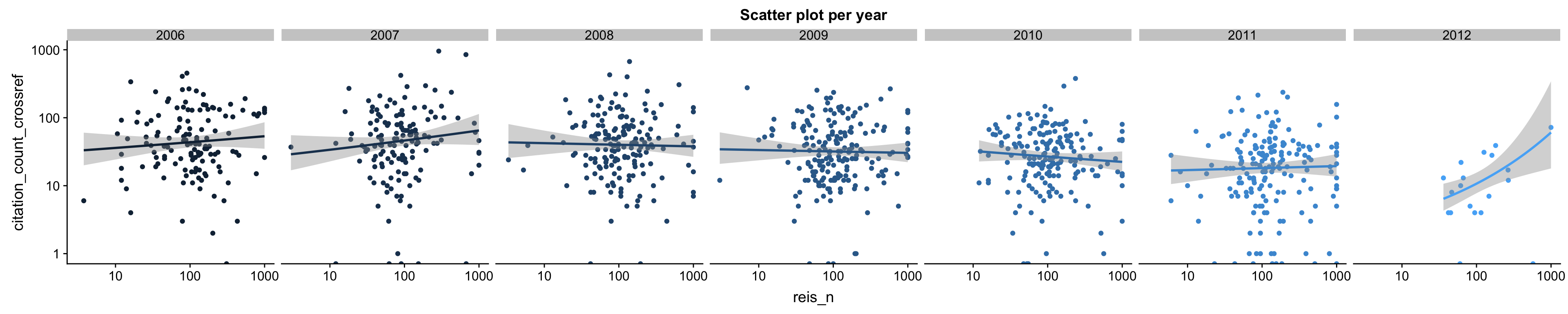
Figure 3: There is no association between N and citations, including for studies that had more years to accumulate citations.
By journal
Maybe we don’t see an association between N and citations in Psychological Science, because some small-N papers are solid vision studies with good power within-subject? In the analysis by journal, we see that there is no association between sample size and number of citations within each journal, including some that focus on personality research only, which is a pretty N-driven area.
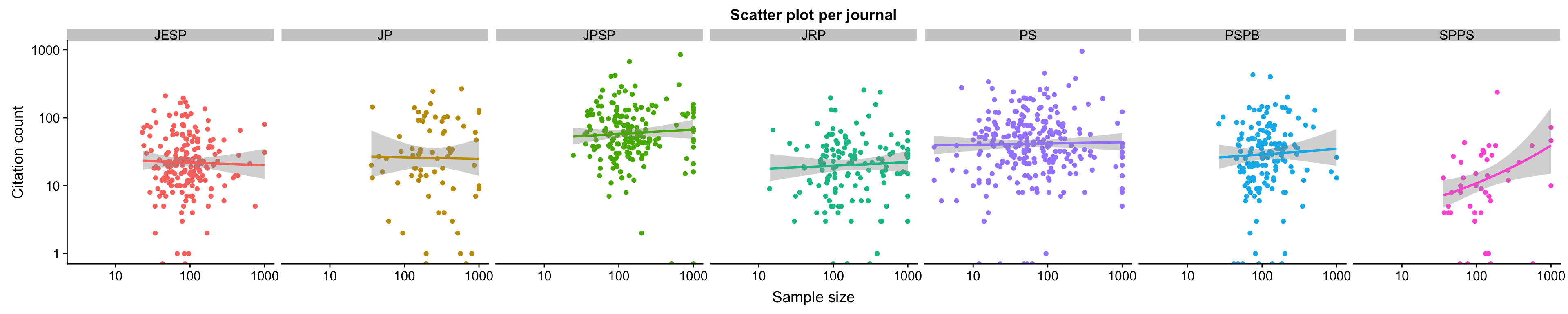
Figure 4: Even in the Journal of Personality and the Journal of Research in Personality, there is no association between N and citations. There appears to be some in SPPS, but the number of studies is small and we should not overinterpret it.
The Spearman rank correlations between sample size and citations by journal tell the same story.
| IF | NF | Journal | k_studies | correlation |
|---|---|---|---|---|
| 21 | 194 | SPPS | 48 | 0.36 |
| 32 | 273 | JRP | 129 | 0.05 |
| 34 | 119 | JESP | 192 | -0.01 |
| 46 | 147 | PSPB | 155 | 0.14 |
| 49 | 334 | JP | 70 | 0.01 |
| 65 | 132 | PS | 269 | 0.02 |
| 85 | 225 | JPSP | 179 | -0.01 |
There isn’t really any perceptible time trend in sample size,3 but it still seems worthwhile to divide the citation count by number of years until 2018 to see whether that makes a difference.
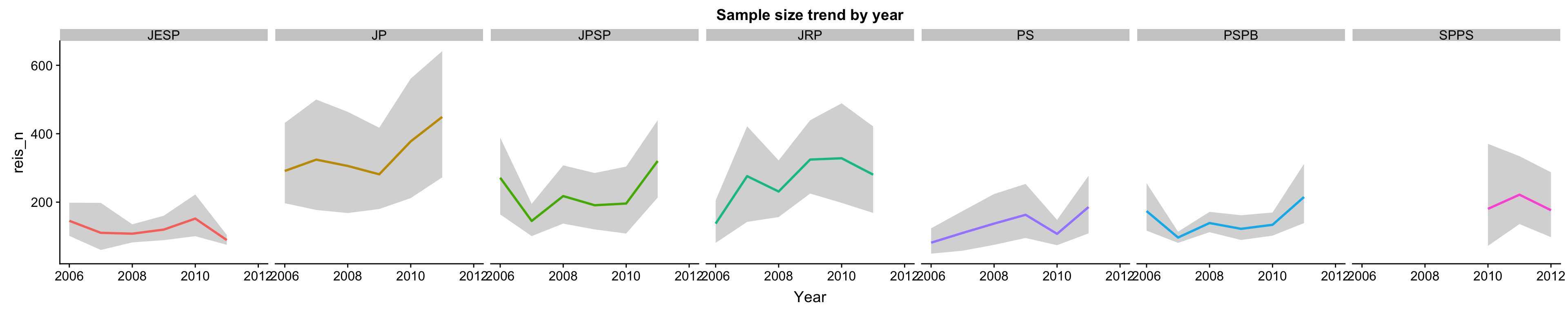
Figure 5: We do not collect bigger samples over time.
It does not.
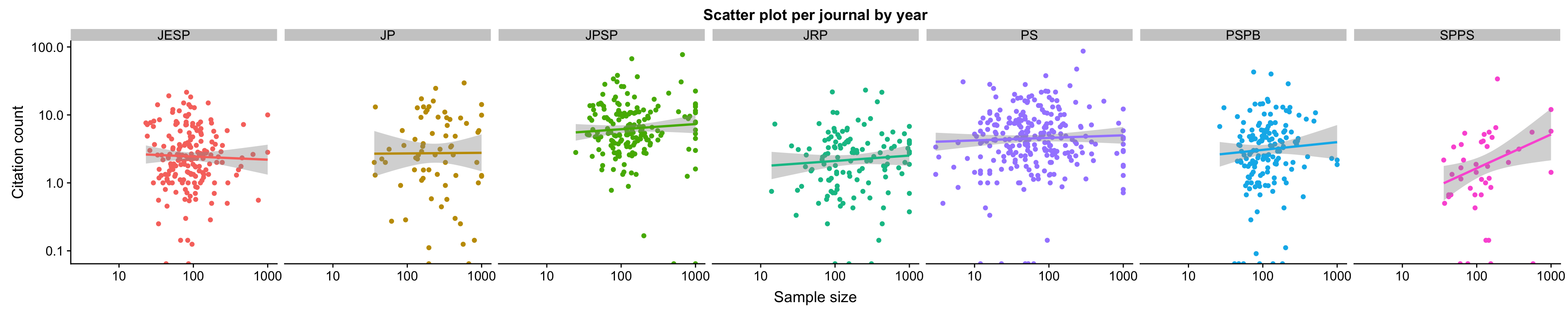
Figure 6: Because there is no sample size trend, citations over years published is not related to sample size any differently than simple citation count.
Maybe the problem is that I ignored the fact that citations are a count variable and did not adjust those correlations for the publication year. Nope!
| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| reis_n | 1.00 | 0.00 | 1.3 | 0.2 | 1.00 | 1.00 |
| Year | 0.83 | 0.02 | -8.1 | 0.0 | 0.79 | 0.87 |
| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| reis_n | 1.00 | 0.00 | -0.37 | 0.71 | 1.00 | 1.00 |
| JournalJP | 1.16 | 0.27 | 0.54 | 0.59 | 0.67 | 1.94 |
| JournalJPSP | 2.08 | 0.17 | 4.36 | 0.00 | 1.49 | 2.90 |
| JournalJRP | 0.83 | 0.23 | -0.78 | 0.43 | 0.53 | 1.30 |
| JournalPS | 1.74 | 0.16 | 3.45 | 0.00 | 1.27 | 2.39 |
| JournalPSPB | 1.17 | 0.20 | 0.76 | 0.45 | 0.78 | 1.73 |
| JournalSPPS | 0.70 | 0.39 | -0.91 | 0.36 | 0.30 | 1.44 |
| Year | 0.85 | 0.02 | -7.49 | 0.00 | 0.81 | 0.88 |
| reis_n:JournalJP | 1.00 | 0.00 | 0.63 | 0.53 | 1.00 | 1.00 |
| reis_n:JournalJPSP | 1.00 | 0.00 | 0.73 | 0.47 | 1.00 | 1.00 |
| reis_n:JournalJRP | 1.00 | 0.00 | 0.46 | 0.65 | 1.00 | 1.00 |
| reis_n:JournalPS | 1.00 | 0.00 | 0.33 | 0.74 | 1.00 | 1.00 |
| reis_n:JournalPSPB | 1.00 | 0.00 | 0.44 | 0.66 | 1.00 | 1.00 |
| reis_n:JournalSPPS | 1.00 | 0.00 | 1.12 | 0.26 | 1.00 | 1.00 |
| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| reis_n | 1.24 | 0.19 | 1.1 | 0.26 | 0.85 | 1.8 |
| Year | 0.85 | 0.03 | -5.6 | 0.00 | 0.80 | 0.9 |
| reis_n:Year | 1.00 | 0.00 | -1.1 | 0.27 | 1.00 | 1.0 |
So, how does sample size relate to citation counts?
There seems to be pretty much nothing there! Maybe we can come up with a post-hoc narrative by looking at all studies and seeing which studies are cited a lot and have large or small samples.
Hover your mouse over the dots to see the study titles. Jean Twenge with her humongous name study is hiding behind the legend, scroll to find her.
My current favourite post-hoc narrative is that citation counts are just very poor measures of importance. I wouldn’t bet that a better measure of importance would correlate with sample size, but I’m fairly convinced by now that citation counts just suck as a metric even of the thing they’re meant to index (impact/importance). I am especially worried about the difference simple citation counts make between a study that is synthesised in a review that then gets cited a lot4 and a study that doesn’t get synthesised in a review. I tried to make the case for a better, more PageRank-y metric, but it would already be interesting to redo my analysis here and from the previous blog post after excluding self citations. Unfortunately, Elsevier still hasn’t given me Scopus API access, and I lack the chops to do anything more fancy. I really hope projects like the Open Citations Corpus lead to such fancy metrics becoming available.
Figure 7: Interactive plot of Ns and citation counts.
Limitations
Well, there are some vision studies in here that used a within-subject paradigm and probably had adequate power for the question they asked anyway. Their small sample size may limit generalizability to other people, but I guess that’s not the dominant question asked in vision science.5 But then again, for some pure-personality journals, we also find no association. There is of course the possibility that studies with very large Ns are more likely to use abbreviated measures, only self-report, and online samples. But then, they are also more likely to be from representative panel studies and online samples aren’t actually any less representative than lab samples. It seems unlikely that any disadvantages exactly balance out with the advantages associated with sample size, so that we arrive at a zero correlation with importance.
List of studies
Thought of something fun to do with the data that I didn’t do here? Grab the data below!
](https://farm3.staticflickr.com/2940/14782389554_3ba3df7683_o_d.jpg)
Figure 8: Ample size ain’t worth it. From the Internet Archive Book Images
Appendix
You can grab the original data on the OSF. Did we get the right DOIs? There are probably still some mismatches and for some, we didn’t find the DOI at all.
I understand this is a presumption, see limitations↩
I hope nobody skims that badly.↩
Ugh, that alone is depressing. Since 2006, so many new tools came on the market. How did that not help?↩
Obviously, reviews aren’t included here, but neither is their reflected glory.↩
Which is consistent with the fact that there are low-hanging fruit like The Dress waiting to be picked in the study of individual differences in vision.↩