Show code
d-title h1 {
font-size: 20px;
}Show code
knitr::include_graphics("figures/treemap_overall.png")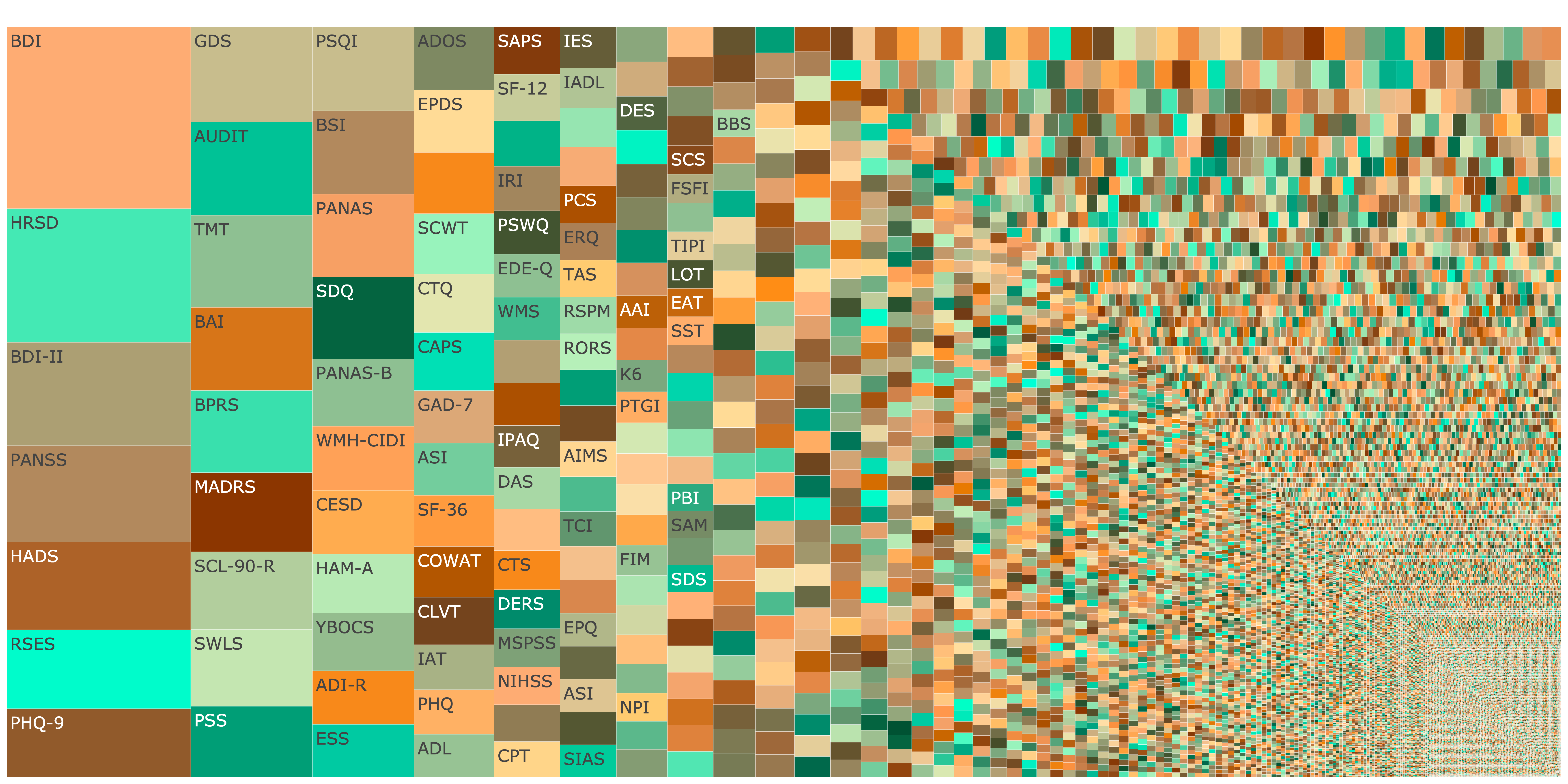
Figure 1: Treemap showing fragmentation across subfields. Hill-Shannon Diversity \(D = 1626.05\)
Click image to open interactive plot.
This online supplement accompanies our preprint. The main figures for the preprint are generated here.
The plots you see here on this page are called treemap plots. In such plots, the area per test is proportional to its usage frequency. The images here are static. If you click them, you can view an interactive plot (give it some time to load) that will allow you to see how often each measure has been used according to APA PsycInfo, and look up the measure in APA PsycTests.
By comparing across the subdisciplines, we can see what higher and lower entropy fields look like visually. High entropy is seen as great fragmentation, i.e. there are many small tiles and many tiles of similar size. Lower fragmentation is apparent when some large tiles reflecting individual measures, such as the Beck Depression Inventory, dominate a field.
Personality and Social Psychology
Fragmentation (Hill-Shannon Diversity) \(D = 919\)
Show code
knitr::include_graphics("figures/treemap_personality.png")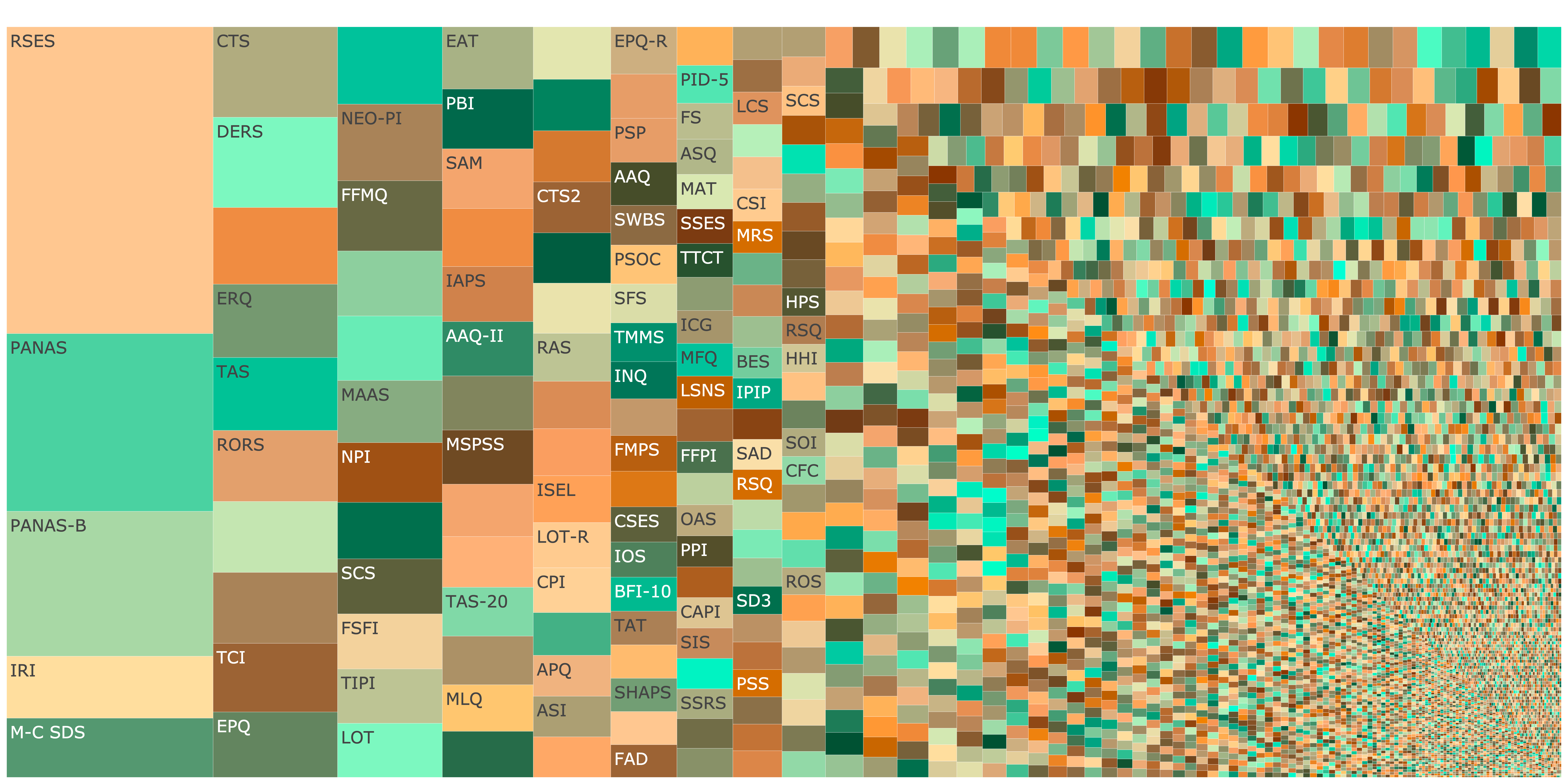
Figure 2: Treemap showing fragmentation across personality and social psychology. Click image to open interactive plot.
Industrial/Organizational Psychology
Fragmentation (Hill-Shannon Diversity) \(D = 671\)
Show code
knitr::include_graphics("figures/treemap_io.png")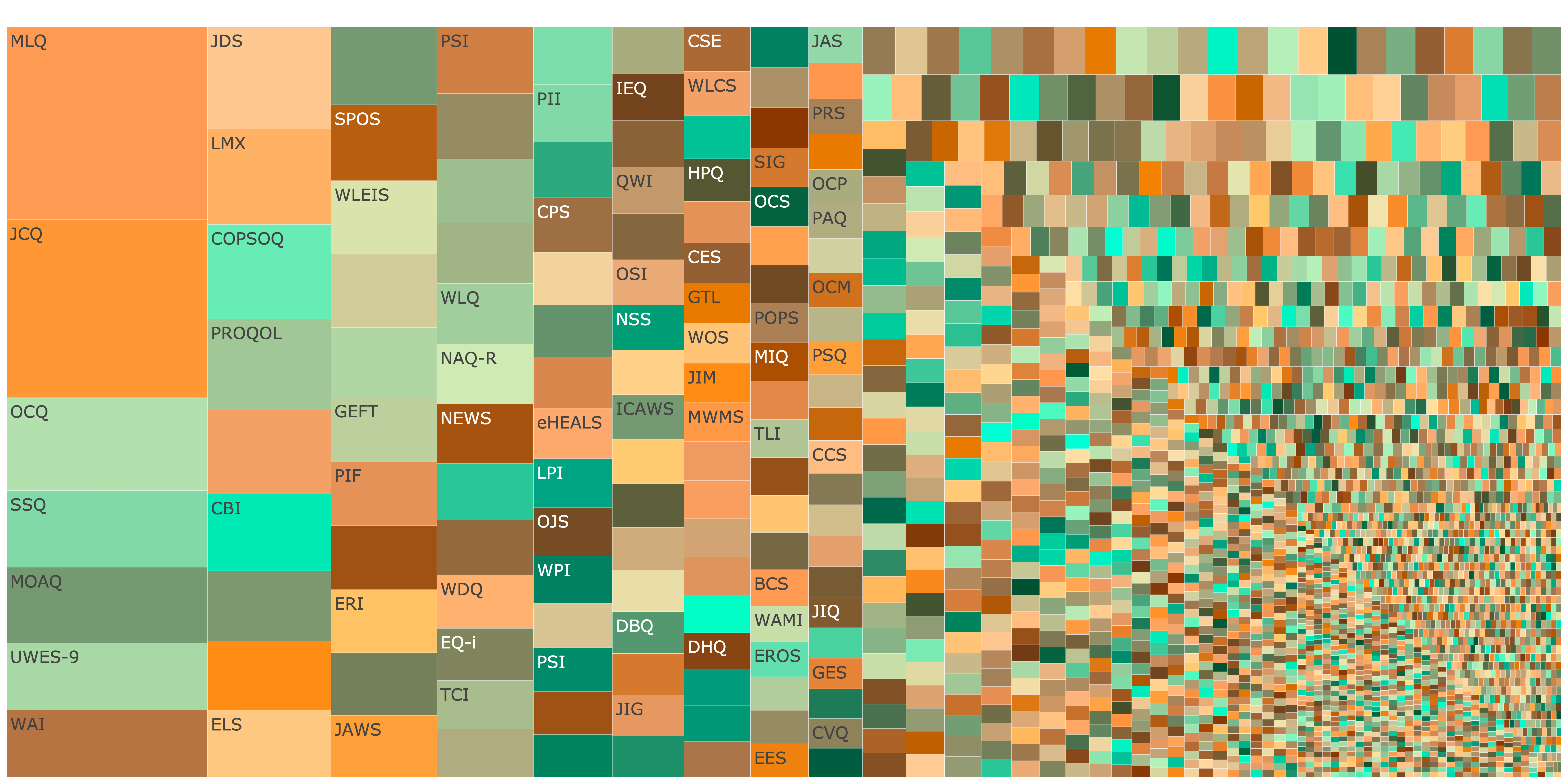
Figure 3: Treemap showing fragmentation across industrial/organizational psychology. Click image to open interactive plot.
Health and Clinical Psychology
Fragmentation (Hill-Shannon Diversity) \(D = 499\)
Show code
knitr::include_graphics("figures/treemap_clinical.png")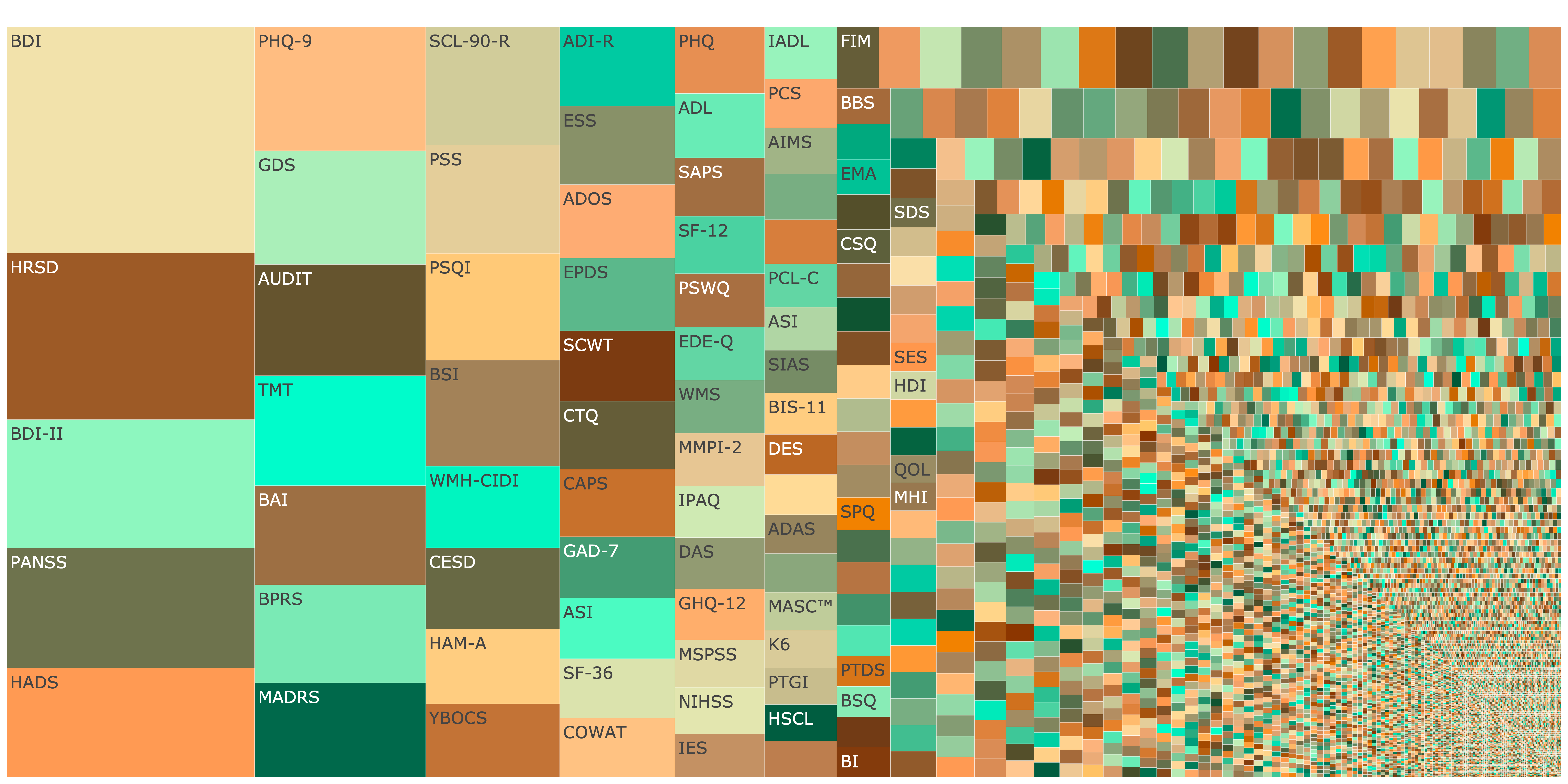
Figure 4: Treemap showing fragmentation across Health and Clinical Psychology. Click image to open interactive plot.
Educational and Developmental Psychology
Fragmentation (Hill-Shannon Diversity) \(D = 429\)
Show code
knitr::include_graphics("figures/treemap_educational.png")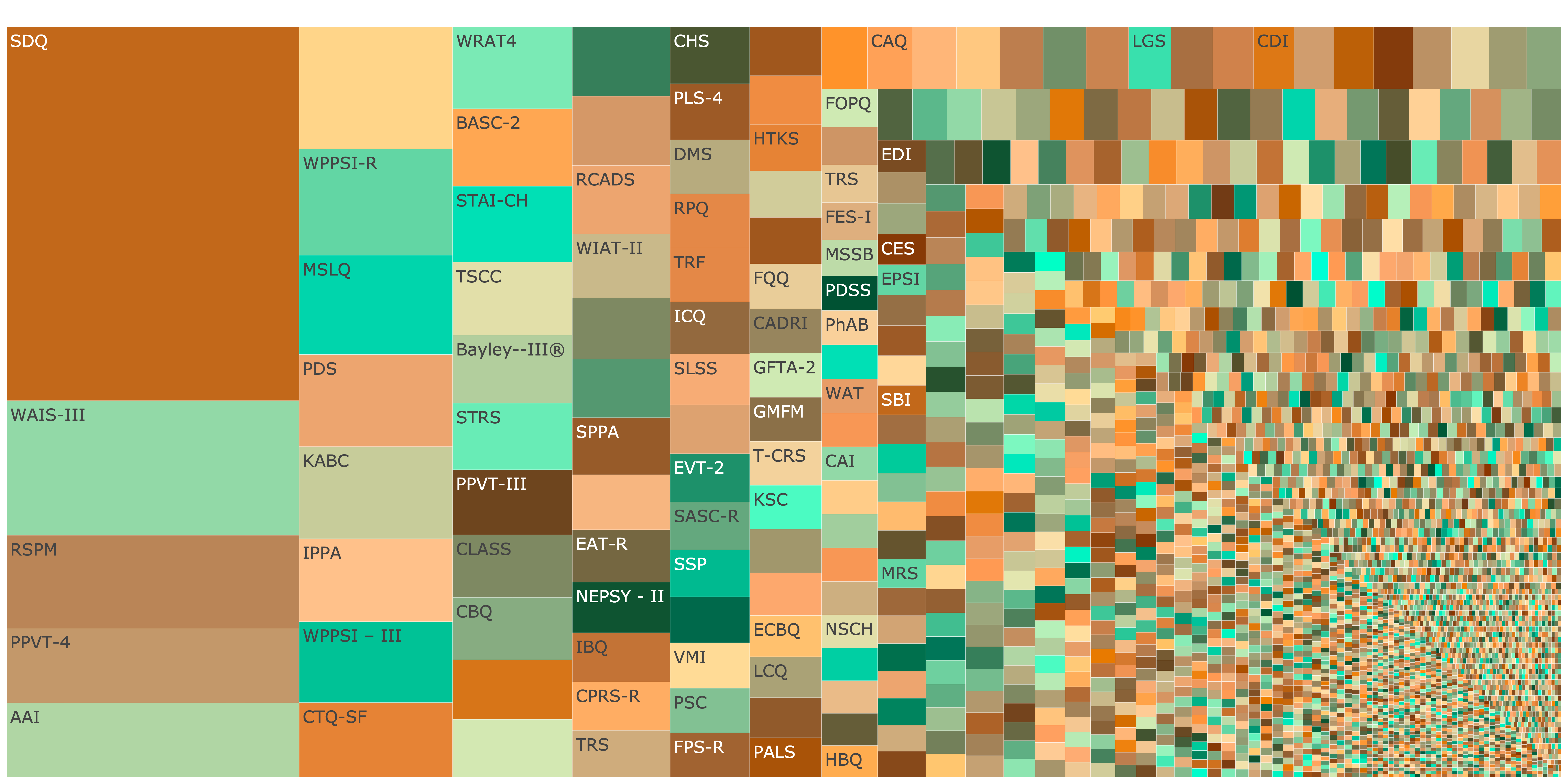
Figure 5: Treemap showing fragmentation across Educational and Developmental Psychology. Click image to open interactive plot.
Cognitive Psychology
Fragmentation (Hill-Shannon Diversity) \(D = 132\)
Show code
knitr::include_graphics("figures/treemap_cognitive.png")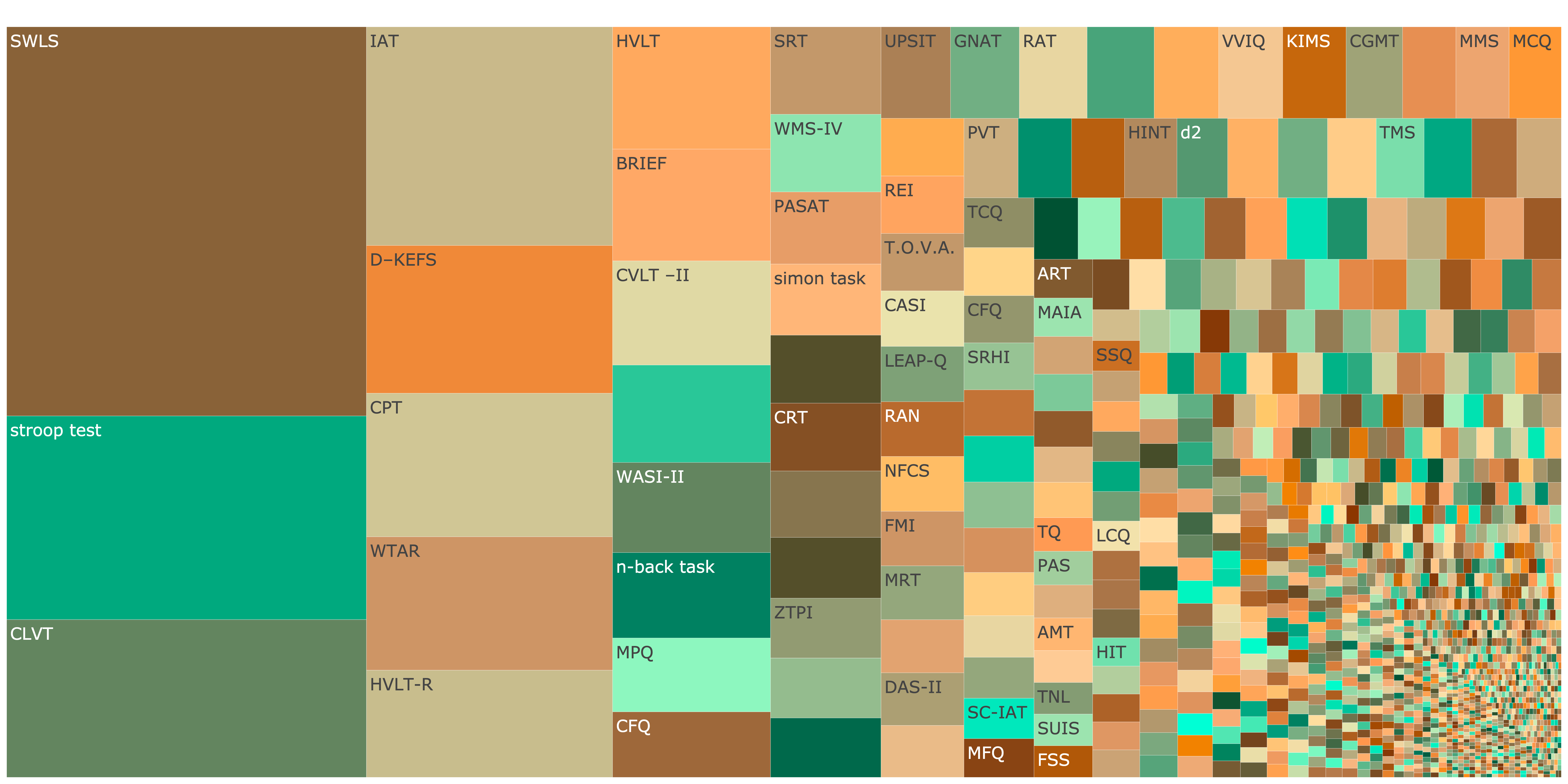
Figure 6: Treemap showing fragmentation across Cognitive Psychology Click image to open interactive plot.