I study genetic and hormonal causes of why people differ and change, especially their personality, intelligence, and sexuality. Open, reproducible science is important to me, so I often work on methods, measures, and transparency and dabble in research software development. I teach research methods at Witten/Herdecke University.
You can reach me at ruben.arslan@gmail.com or on Bluesky. If you want to tell me I’m wrong about something anonymously, you can use this form.1 I also have a standing bug bounty policy for errors in my published work.
Publications
Here’s a usually slightly outdated PDF of my curriculum vitae. All my work is at least green open access and you can find direct links to each publication in this PDF (click on the green/orange lock icons). You can also find my publications on my Google Scholar profile.
I often make websites to document my analyses and results. You can click on the graphs below to view them.
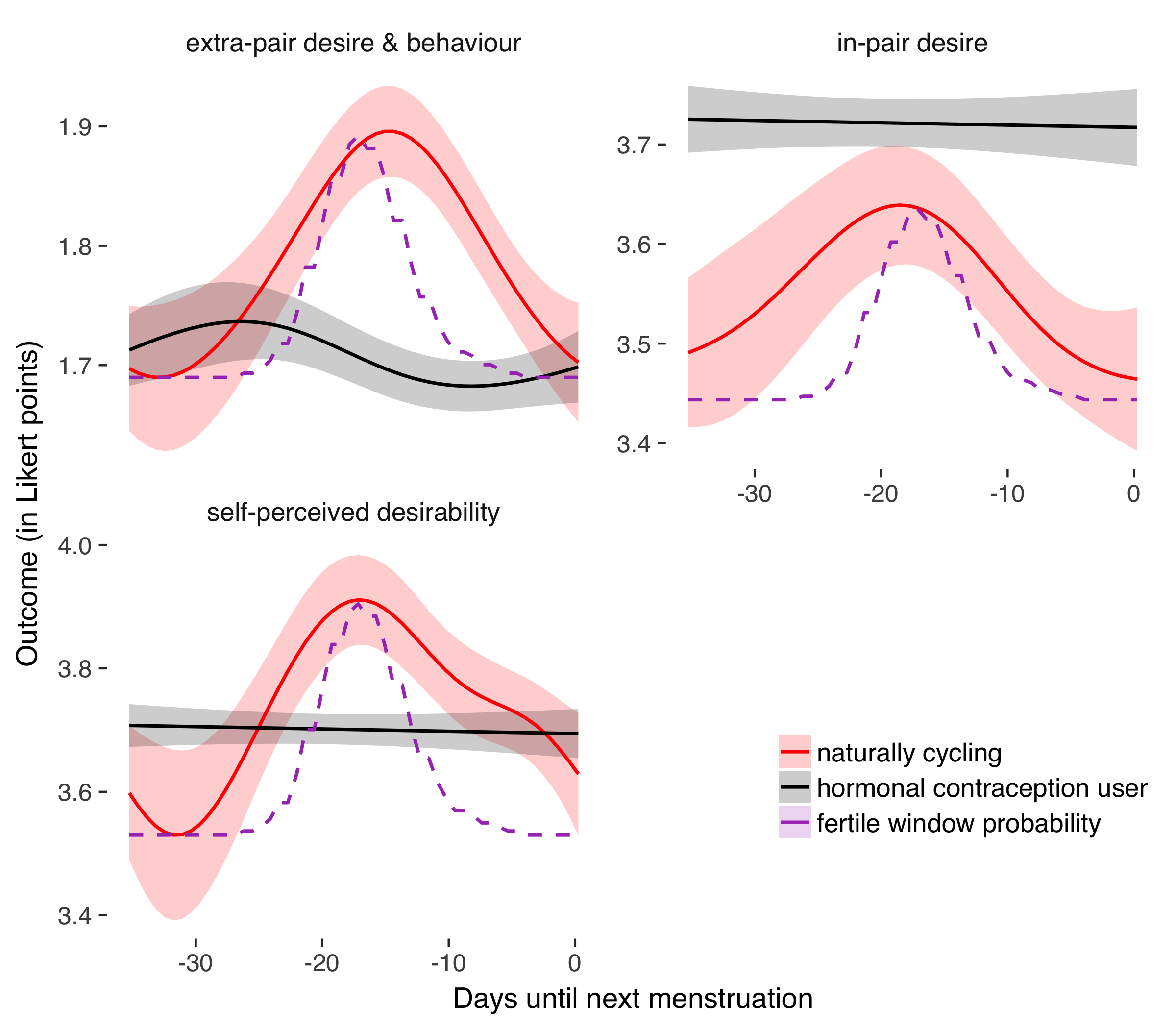 From ‘Using 26 thousand diary entries to show ovulatory changes in sexual desire and behaviour.’ (2017), PDF
From ‘Using 26 thousand diary entries to show ovulatory changes in sexual desire and behaviour.’ (2017), PDF
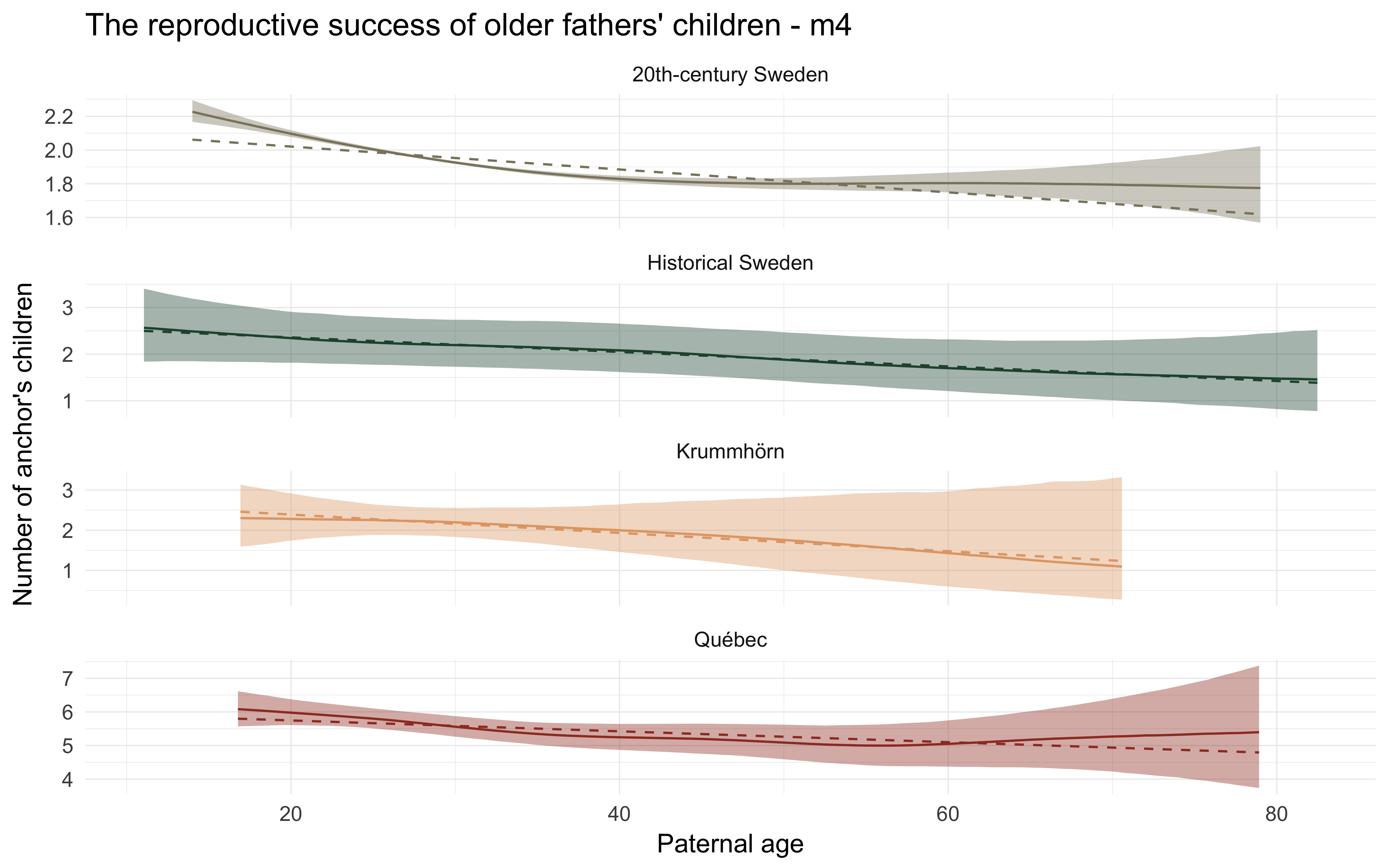 From ‘Older fathers’ children have lower evolutionary fitness across four centuries and in four populations.’ (2017), PDF
From ‘Older fathers’ children have lower evolutionary fitness across four centuries and in four populations.’ (2017), PDF
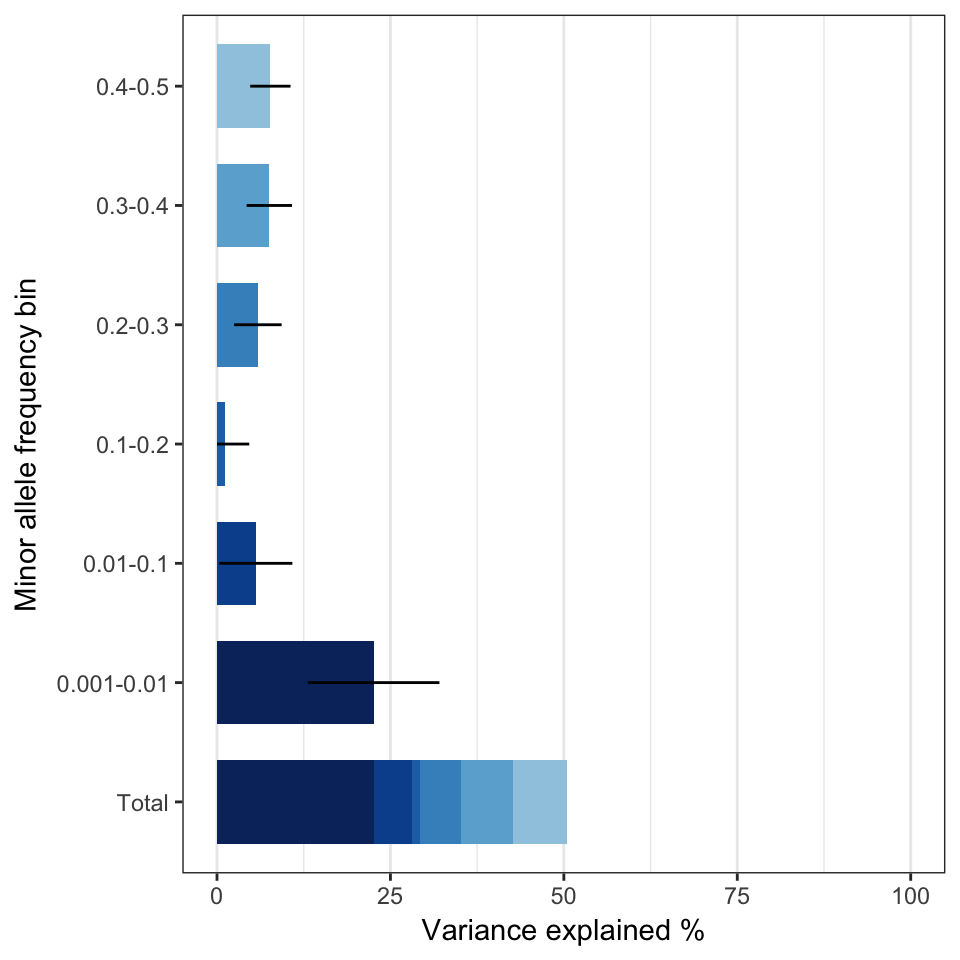 From ‘Genomic analysis of family data reveals additional genetic effects on intelligence and personality’ (2018), PDF
From ‘Genomic analysis of family data reveals additional genetic effects on intelligence and personality’ (2018), PDF
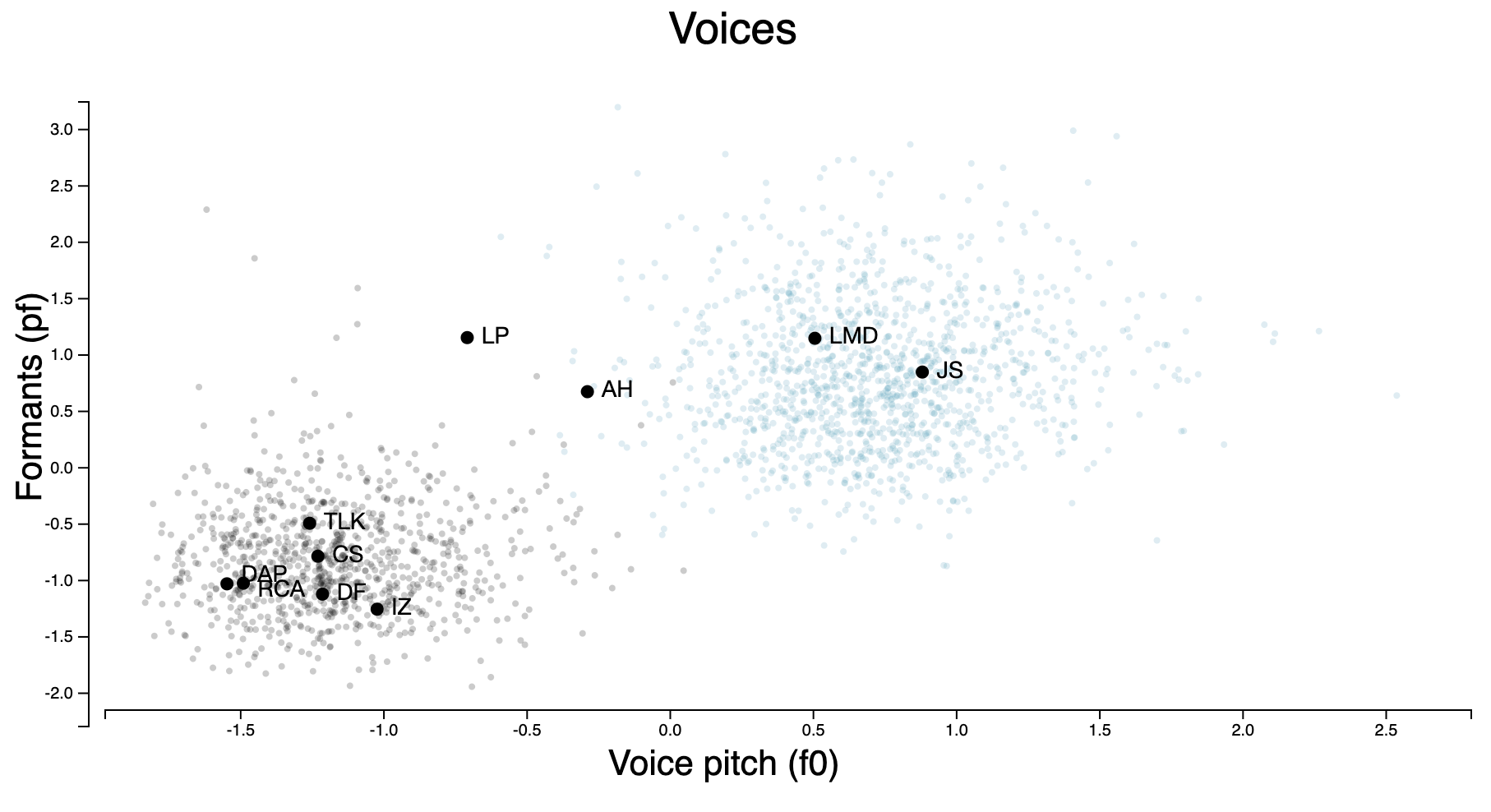 From ‘Do voices carry valid information about a speaker’s personality?’ (2021), PDF
From ‘Do voices carry valid information about a speaker’s personality?’ (2021), PDF
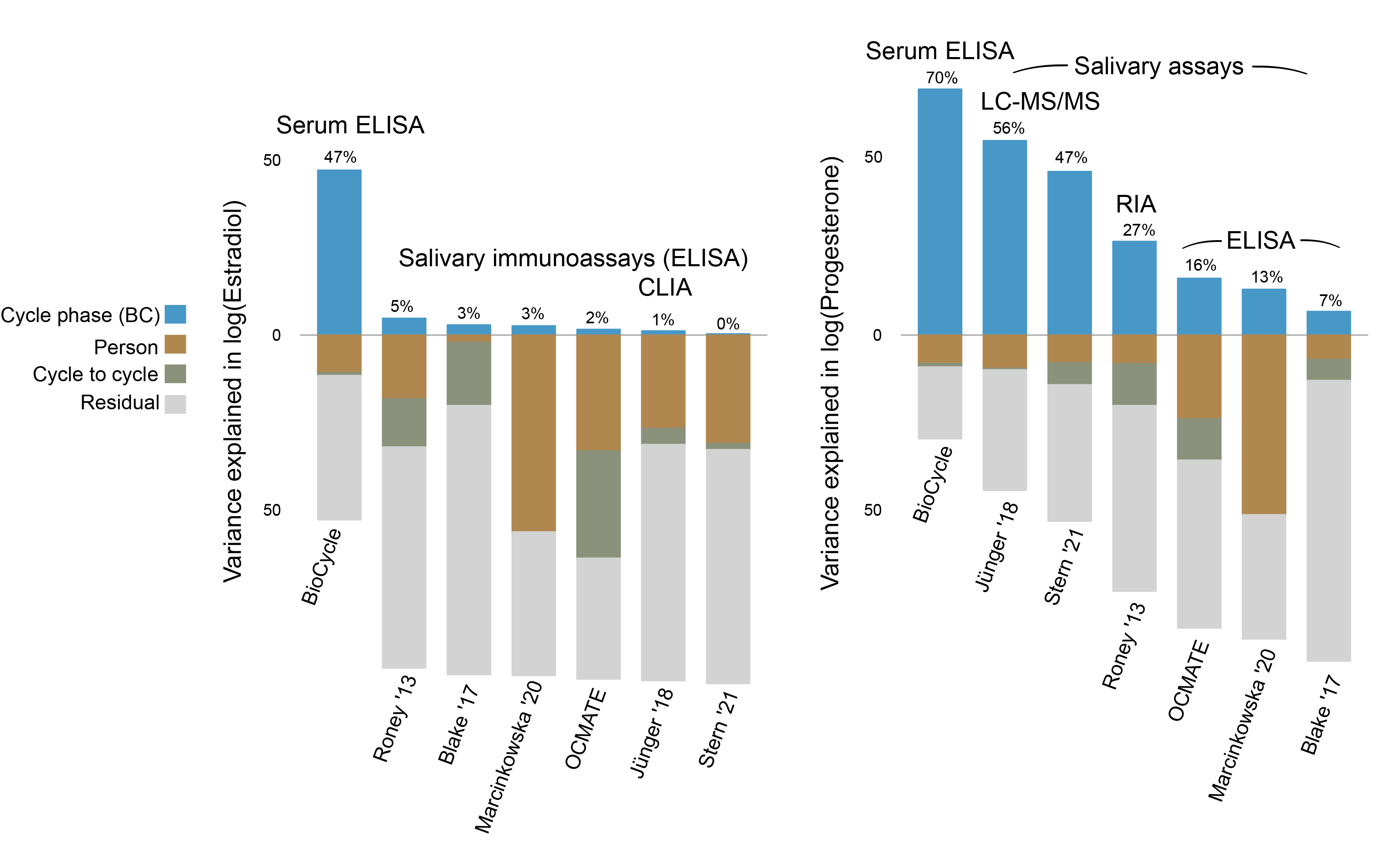 From ‘Not within spitting distance: salivary immunoassays of estradiol have subpar validity for predicting cycle phase.’ (2023), PDF
From ‘Not within spitting distance: salivary immunoassays of estradiol have subpar validity for predicting cycle phase.’ (2023), PDF
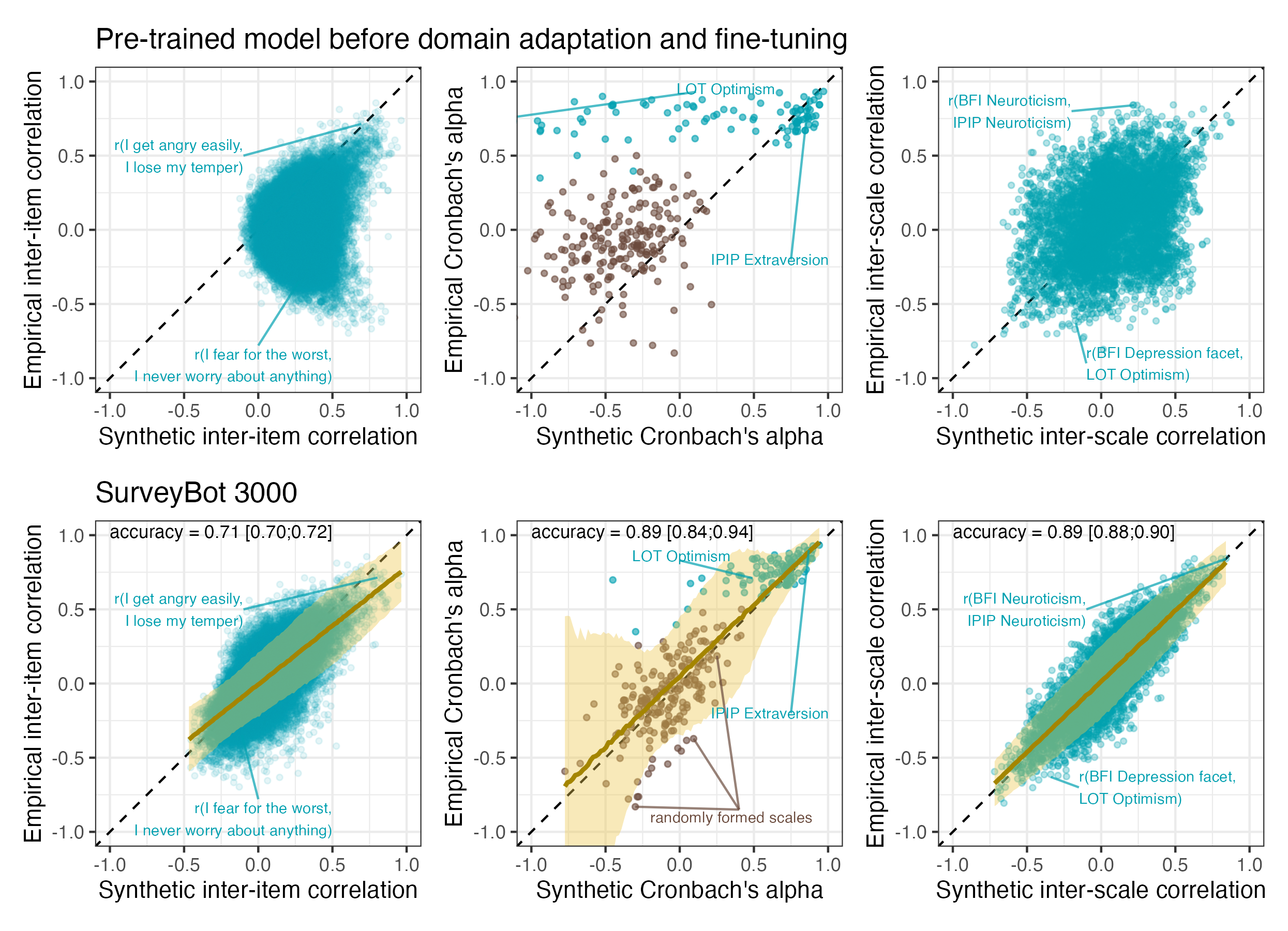 From ‘Language models accurately infer correlations between psychological items and scales from text alone.’ (2025), PDF
From ‘Language models accurately infer correlations between psychological items and scales from text alone.’ (2025), PDF
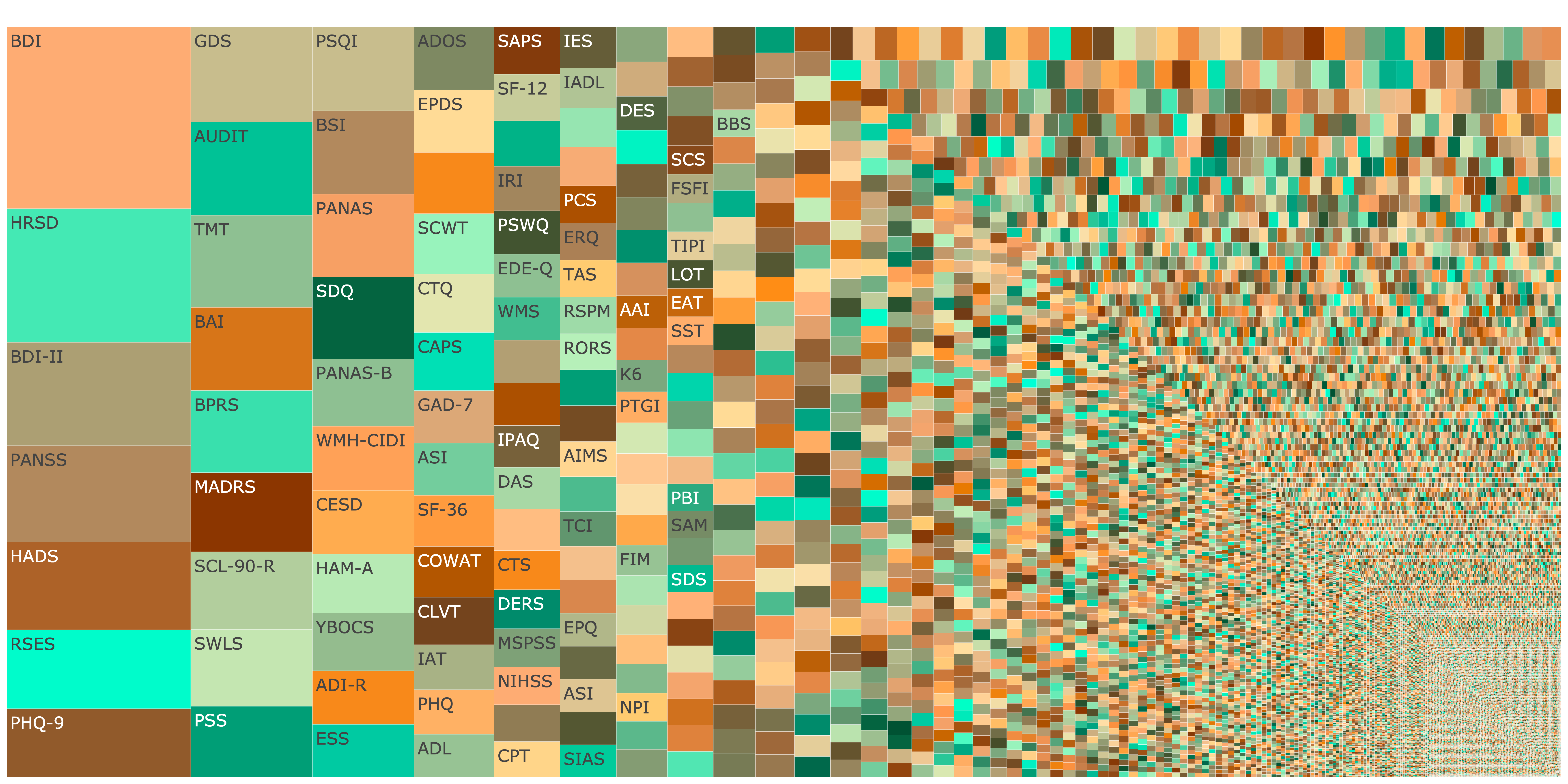 From ‘A fragmented field: Construct and measure proliferation in psychology.’ (2025), PDF
From ‘A fragmented field: Construct and measure proliferation in psychology.’ (2025), PDF
Blogs
Together with three wonderful people, I founded The 100% CI, a blog focused on open science and meta science. Posts that I wrote primarily, can be found here, although we all edit and review each other. My personal blog features some small analyses, simulations, post-publication criticism, and accounting for errors in my work. The blog’s name (One lives only to make blunders) is taken from this famous letter from Darwin to Lyell.
Open Science
I’m a child of the reproducibility crisis in psychology - I had to unlearn much of what I was taught. To me, the open science movement is our best hope to fight the corruption of science. I occasionally give talks and workshops to advertise and teach tools and methods to do better work, including some of the software listed below.
Bad Science vs. Open Science
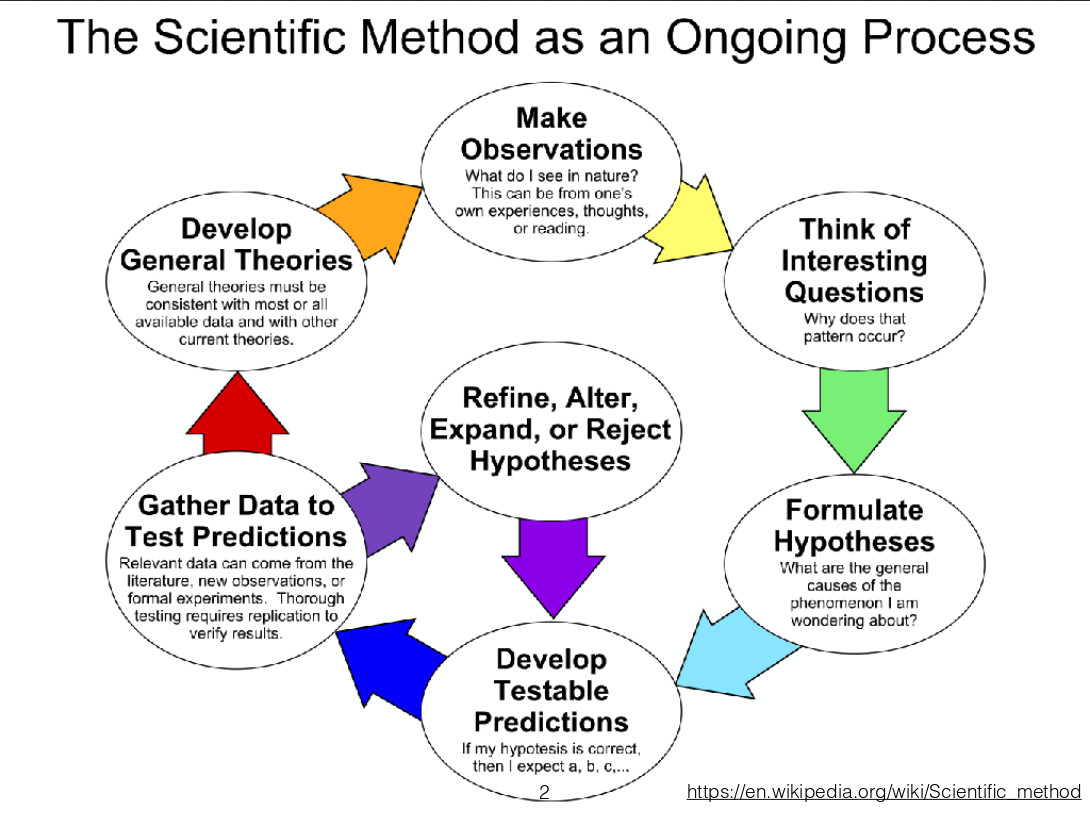
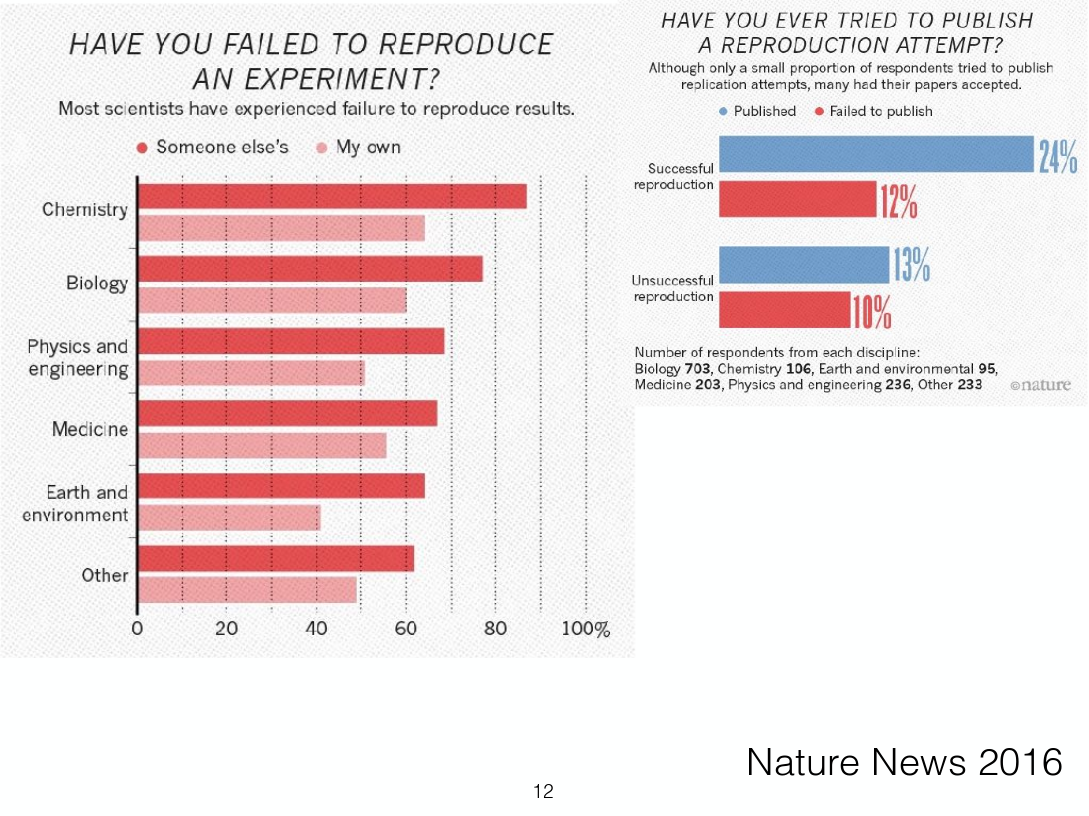
The replication crisis and possible reforms. This is my main introductory talk that I have given in Greifswald, Copenhagen, Berlin, and Göttingen. I try to take slightly less than half of the time for the problems, and slightly more than half for the solutions.
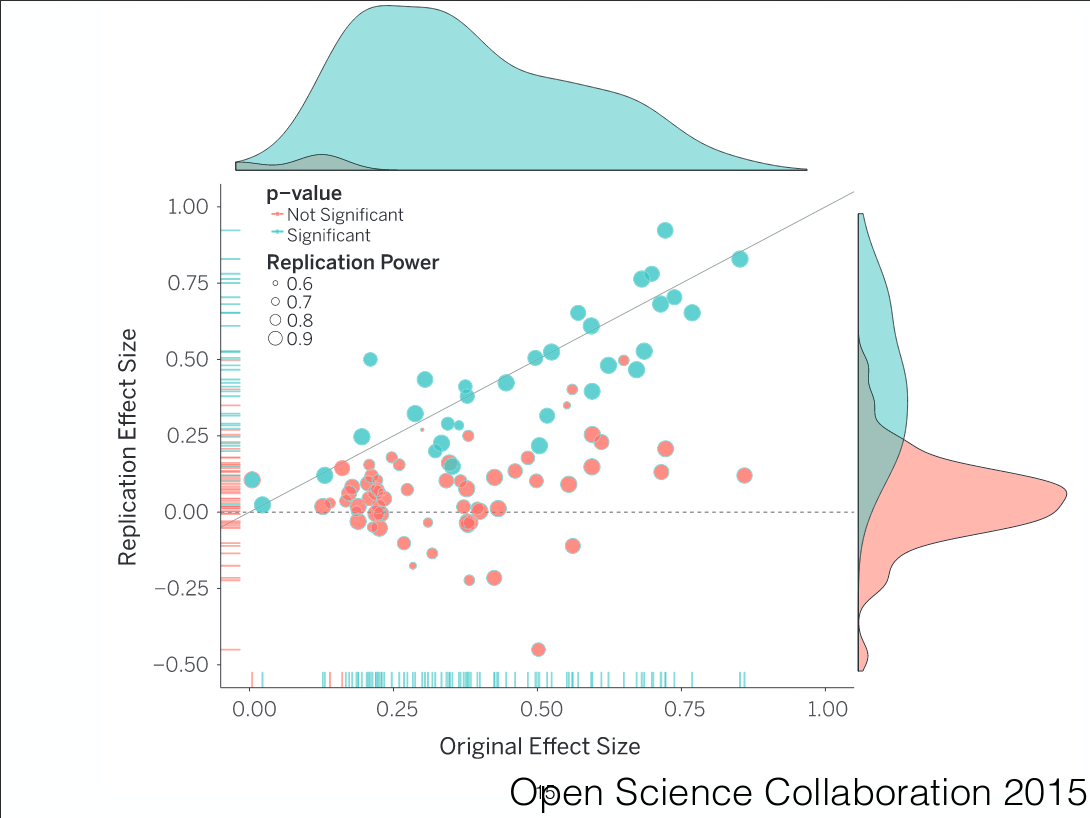
Abstract
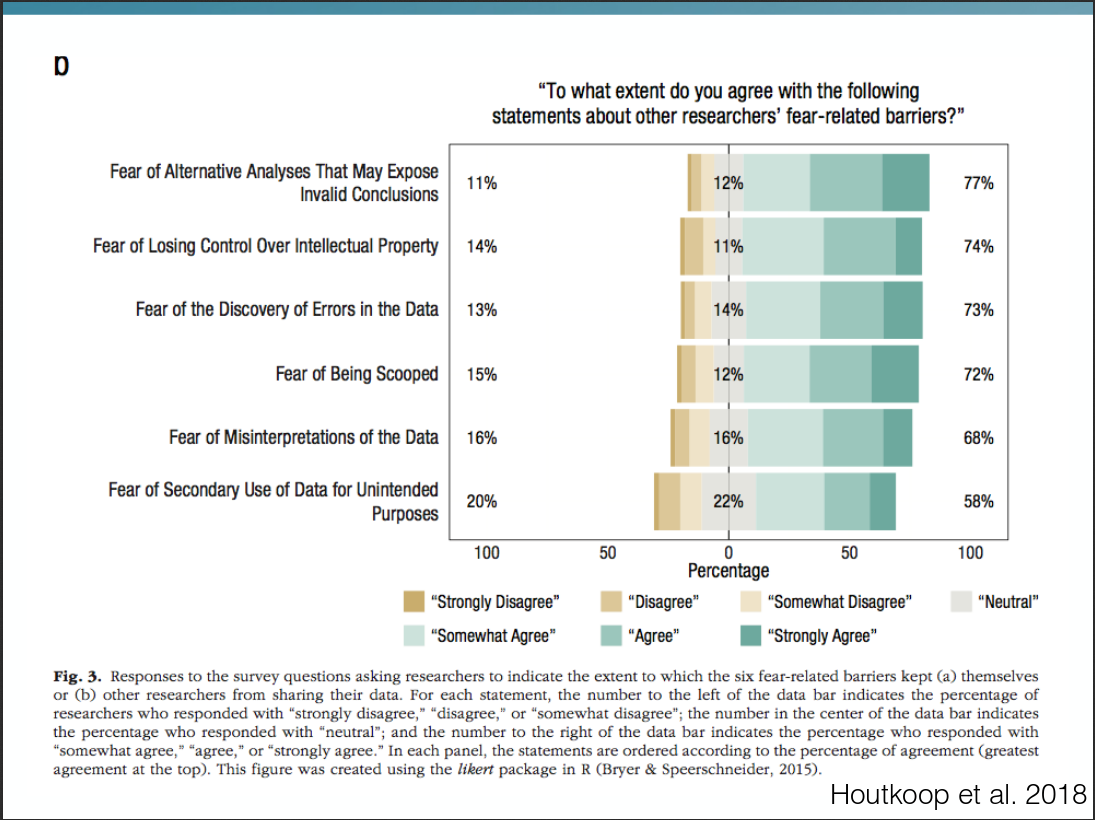
Estimates from large-scale replication projects in psychology suggest that the majority of studies from top journals do not have replicable results. In related news, researchers were able to publish highly significant support for impossible phenomena using commonly accepted scientific research methods. Data detectives keep finding highly cited scientific papers that are riddled with errors invalidating their conclusions. Our textbooks are full of findings that do not replicate or are in serious doubt. Publication bias and outcome switching contaminate our knowledge base about pharmacological and psychotherapeutic treatment. Science as a system has issues, but can we use the scientific method to remedy them? A vibrant reform movement is seeking to do so, but it can be hard to keep track of all the suggestions to do better. I outline concrete plans and paths that could lead to lasting improvements, such as the Open Science Framework, Registered Reports, the Peer Reviewer’s Openness Initiative, the All Trials initiative, preprints, post publication peer review, and guideline and incentive setting at the journal, hiring and funding level.



Workshop on FAIR metadata
Abstract
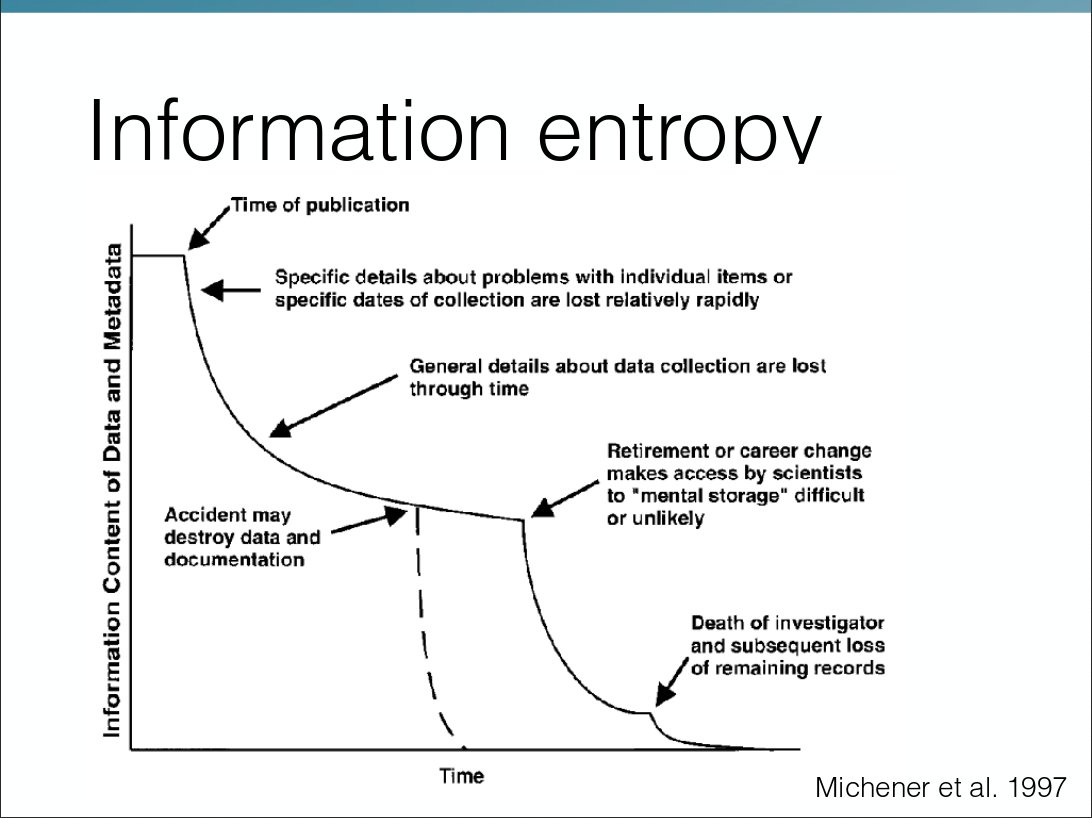
Google now also finds datasets – but will it find yours? How can you share your data in such a way that it will be useful to you and others in the future? Some scientific disciplines have found ways to store data in standardised formats in central, open repositories. But for many, especially in health and human subjects research, data cannot be shared openly. You can always share metadata – but how do you do so in a forward-thinking way? We discuss standards or the lack of them and try out practical tools.



formr workshop
Abstract
The survey framework formr.org is a free, open source software for online and lab studies. Even with little or no programming skills users can design complex studies. Key features include automatic email and text message reminders for repeated surveys on computers and smartphones and the automatic generation of personalised graphical feedback based on R functions. Designed by and for personality researchers, formr.org makes it easy to collect peer ratings, social networks, dyadic and round robin data, longitudinal, and experience sampling data. It also allows for separation of contact and study data as required by European privacy laws. Users of formr.org can increase the transparency and reproducibility of their research by sharing and version tracking complete study workflows. Furthermore, data collected with formr.org can be cleaned and documented in human- and machine-readable codebooks without additional effort by relying on the study metadata.




Maintaining privacy with open data
Abstract
In this workshop, we will try to tackle questions about privacy in the age of big and open data. Why should we even share our data? For what kind of research data do we need to maintain privacy? What is personally identifiable information and why is not sufficient to omit it to make data truly anonymous? How do we assess the risks of re-identification? How do we maintain our participants’ anonymity, when we need to stay in touch with them online? What novel risks are engendered by the massive trail of data we all leave on the web? How do we anonymise already collected data by binning, fuzzing, and omitting? We will also discuss novel technological solutions that can permit us to share data openly: synthetic data generation, scientific use files, or differential privacy algorithms. The workshop consists of some theoretical input, but will also focus on practical exercises. Ideally, participants bring their own laptop with a current R installation. Furthermore, participants can send in questions or typical scenarios from their own research fields in advance.](figures/privacy.jpg)
Figure 1: Transparency vs. privacy. From the Internet Archive Book Images
Software
I have published a few tools, mostly written in PHP, Javascript, or R, all of which are free to use, and two of which are open source. Missing from this list is one website that I had to take offline because a German dictionary didn’t get the joke and threatened to sue me. Don’t ask. You can find the open source software and some of my reproducible statistical analyses on Github and OSF.
formr.org
formr.org is an open source study framework. Most users use it to run fancy surveys with feedback and control complex studies, such as experience sampling, and longitudinal research. I started working on an early version of this before my PhD and continued developing it during my PhD. Core niceties include that a direct link to R allows users to program studies with fairly unlimited complexity. Cyril Tata is helping me develop and maintain the software since 2015. I also wrote an R package simply called formr to help users make the most of the data and metadata. Recently, I’ve added the ability to turn studies into small phone apps that can send push notifications.
In addition to extensive documentation supplied by us and supplemented by our users in a Wiki, there is also a paper describing the software.
codebook
codebook is an R package that allows users to document datasets in nice websites that can be read and understood both by co-authors, forgetful future yous, and machines. It was based on a set of convenience functions available in formr. It can make good use of existing metadata, such as item data contained in Qualtrics or formr.org surveys, but also variable and value labels, in Stata, SPSS, and SAS files.
I wrote a tutorial, but the easiest way to get going is to simply upload a dataset to this webapp. Iro Eleftheriadou created a gallery for codebooks made from datasets uploaded to the Open Science Framework.
Alphabattle.xyz
A small collaboration with a friend led to this player-vs-player online word game written with Meteor. You have to infer the other person’s secret word by asking words, but only learning whether letters matched or not. We kept it very similar to the paper-pencil version that we used to play before it became less common to carry paper and pencil than a smartphone. It predates Wordle.
brainfunnel.com
During a year abroad in Sweden in 2005, I tried to speed up my vocabulary learning using spaced repetition and habit forming (I probably learned more PHP and Javascript than Swedish because of this). Because most existing software that I could find was commercial and didn’t work on Macs, I wrote one in the form of a website. I stopped working on this in 2011. I think it might still be the only one with easy support for gap texts.
Privacy Policy
See here